
The Library of Congress has developed new tools to transfer large quantities of digital content. During 2008, the Library used these tools to add approximately 80 terabytes to its digital collections.

From the video, "Bagit: Transferring Content for Digital Preservation."
As described in the Library of Congress's video, Bagit: Transferring Content for Digital Preservation, the sender of a digital collection prepares for the transfer by packaging the collection and making it accessible for the Library to download. The Library prefers data packaged into standardized "bags," a means of organizing and containing data for transfer as described in the BagIt specification.
Bags are based on the concept of "bag it and tag it," where a digital collection is packed into a directory (the bag) along with a machine-readable manifest file (the tag) that lists the contents. Bags have a sparse structure that envelopes any institutional data architecture and format. It can hold documents, pictures, music, movies and even other folders. Anything digital can fit into a bag.
A bag is like a folder or directory on a computer. It is essentially comprised of three elements: A bag declaration text file, which is like a seal of authenticity; a text-file manifest listing the files in the collection; and a subdirectory – usually titled “data” – filled with the digital content. The manifest is machine readable for automated data ingest. The receiving computer analyzes the manifest and runs checksums on the contents; if the checksums match, the transfer is successful.
A bag can also contain an optional text file, titled "bag-info.txt," that contains a small amount of administrative metadata, such as contact information for the collection owner and a brief description of the collection. Users can include much more metadata about the collection, but the Library recommends storing it in the "data" directory with the rest of the collection in order to keep the bag root directory uncluttered. Users can note in the "bag-info.txt" file that additional metadata exists and resides in the "data" directory.
The Library prefers network data transfer because this method is much faster and easier than hardware-media transfers. The Library prefers to download digital collections rather than have the sender upload it to the Library. One of the advantages of downloading is that the data can be accessed from wherever it is stored, whenever convenient.
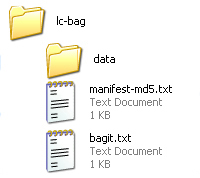
Basic contents of a digital bag.
A bag filled with content is considered complete. A variation, called a holey bag, is gaining wider acceptance because of its flexibility. A holey bag has the standard bag structure but its "data" directory is empty. The holey bag contains an additional text file titled "fetch.txt" at the root level that lists the URLs of the files to be fetched (so-called "holes" in the digital collection to be filled in). A script consults the "fetch.txt" file, follows the URLs, downloads the files and aggregates them into the local "data" directory within the bag. The sender’s source files do not need to reside in the same directory or on the same server; they can be retrieved from many different sources. A holey bag becomes complete after the digital collection is entirely downloaded and its manifest file is verified.
The software used to facilitate the data movement is open-source, well documented and easy to use. After testing several transfer tools and protocols, the Library currently favors HTTP, rsync, FTP and SSH. Desirable features of a good tool are the ability to re-start a transfer from where it left off, if the transfer is disrupted, and the option to parallelize transfer streams.
The Library optimizes broadband network capabilities by downloading the digital collection in several simultaneous parallel streams, resulting in a quick delivery time. Parallelization maximizes the transfer process by splitting data into dozens of multiple concurrent streams or threads, rather than by pushing all the data over the network in a single stream. An optimized network, at least the cabling itself – the "pipes" – should have a sufficient capacity to maximize the data flow from the server to the Internet.
With each digital-collection transfer, the Library refines its tools, simplifying and improving them in iterative stages. Currently the tools are manual and rely on UNIX commands but the Library is working on a next generation of user-friendly browser-based tools to help automate and accelerate the transfer of digital collections over the network.
Read more about the Library’s bag-related data transfer tools.